看到ambry的设计文档,粗略做了下笔记,还没看代码实现,部分理解可能有出入。
LinkedIn的分布式对象存储系统 Ambry介绍
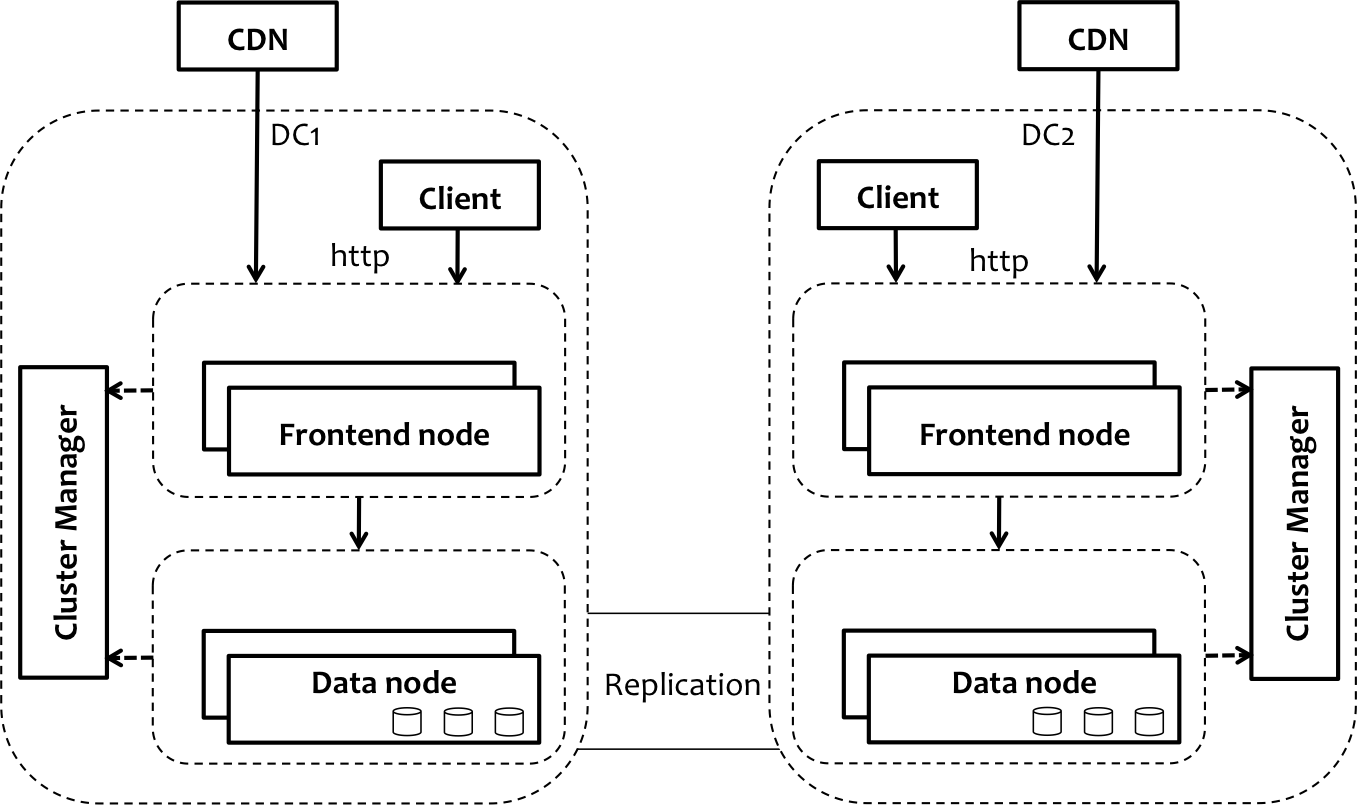
Ambry由三部分组成,分别是用来存储和检索数据的一组数据节点,路由请求的前端机器(请求会在一些预处理之后路由到数据节点上)以及协调和维护集群的集群管理器。数据节点会在不同节点之间复制数据,同时支持数据中心内部和数据中间之间的复制。前端提供了支持对象PUT、GET和DELETE操作的HTTP API。另外,前端所使用的路由 库也可以直接用在客户端中,从而实现更好的性能。在LinkedIn,这些前端节点会作为CDN的原始服务器。ambry官方文档
Clustermap
Clustermap控制拓扑结构、维护状态并帮助协调集群的操作.数据节点和前端服务器都能够访问clustermap,并且会始终使用它们当前的视图来做出决策,这些决策涉及到选择可用的机器、过滤副本以及识别对象的位置等
- 硬件布局:包含了机器的列表、每台机器上的磁盘以及每个磁盘的容量。布局还维护资源的状态(机器和磁盘)并指定主机名和端口,通过主机名和端口就能连接到数据节点
- 分区布局:包含了分区的列表、它们的位置信息以及状态。在Ambry中,分区有一个数字表示的ID,副本的列表可以跨数据中心。分区是固定大小的资源,集群间的数据重平衡都是在分区级别进行的
partiton layout
partition ID | state | replica
————-|————|—————————————————
partition_0 | read/write | DC1:node1:disk_0 DC1:node4:disk_1 DC2:node2:disk_0
partition_1 | readonly | DC2:node0:disk_0 DC1:node4:disk_3 DC2:node2:disk_2
存储
索引本身也是持久化的文件,会定时更新,更新之间的时间窗之内的时间可以通过读取日志来重建。检查点应该对应持久化的索引文件组。
磁盘log引入可以让写入顺序化,减少磁盘碎片
疑问
- 节点有文件删除,则日志中应该有数据可以丢弃,如何释放这部分空间
- 这里包含很多优化,不知道是什么
持久化
- 磁盘上的每个副本均被建模为预先分配的log(preallocated log),通过fallocate创建大文件,然后在里面append写入,保证顺序写入。
- 所有新的消息都会按照顺序附加到log上,消息是由实际的对象块(chunk)和相关的元数据(系统和用户)所组成的。
- 这能够使写入操作实现很高的吞吐量,并且避免出现磁盘碎片。
- Ambry会使用索引将对象id与log中的消息映射起来,索引本身是一组排序的文件片段,条目按照最新使用在前,最旧的条目在后的顺序,从而便于高效查找。
- 索引中的每个条目都维护了log中消息的偏移量、消息的属性以及一些内部使用的域。
- 索引中的每个片段会维护一个bloom filter,从而优化实际磁盘操作所耗费的时间;
- 索引只有最新几个载入内存,其他都是map到内存地址,需要时才会读
零拷贝
- 通过使用sendfile API,在进行读取时,字节从log转移到网络的过程中实现了零拷贝。
- 通过避免额外的系统调用,实现了更好的性能,在这个过程中,会确保字节不会读入到用户内存中,不必进行缓存池的管理
- 读加速通过CDN,因此这里不需要读缓存
恢复
- 因为系统和机器会出现宕机,磁盘上的数据也有可能会损坏,所以有必要实现恢复(recovery)的功能。
- 在启动的时候,存储层会从最后一个已知的检查点读取log,并重建索引。
- 恢复也有助于重建内存中的状态。Log是恢复的来源,并且会永久保存
复制
- 存储节点还需要维护分区中各副本的同步。
- 每个节点上都会有一个复制服务(replication service),它会负责保证本地存储中的副本与所有的远程副本是同步的。
- 在这里,进行了很多的优化,以保证复制过程的高效可靠
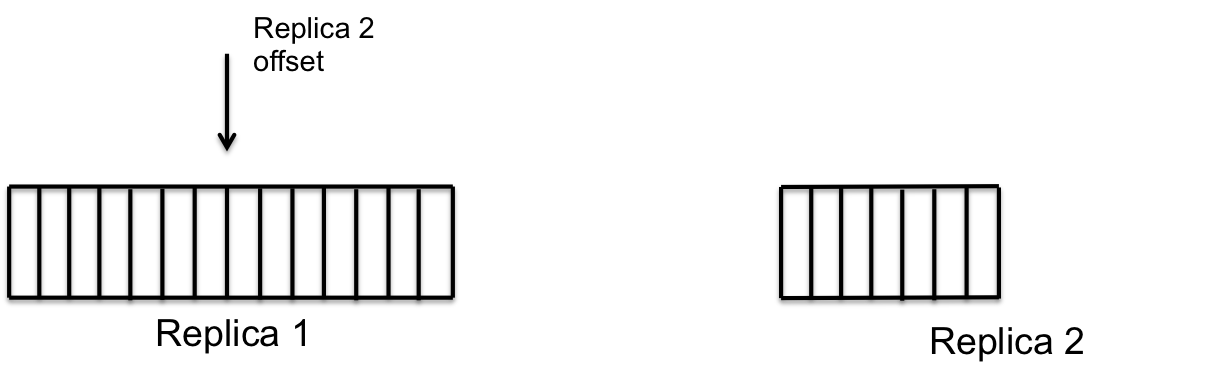 step1
step1 step2
step2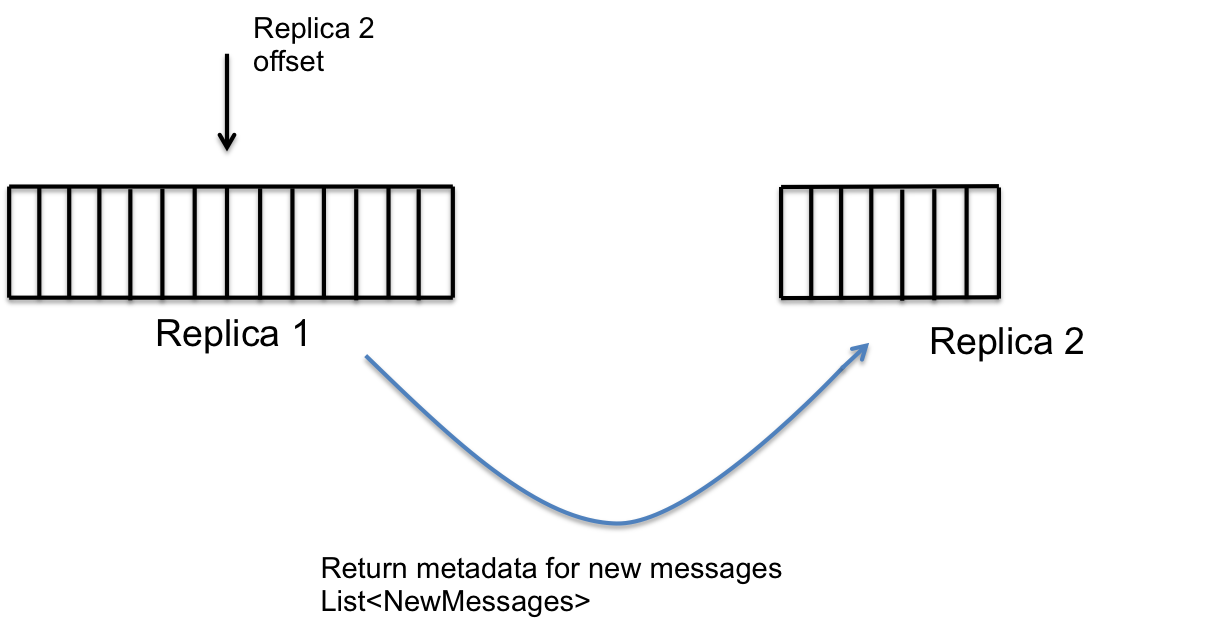 step3
step3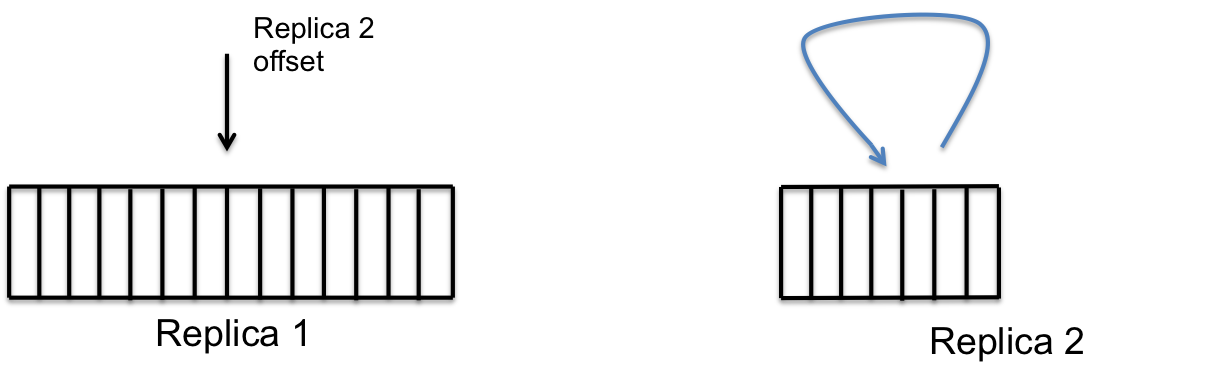 step4
step4 step5
step5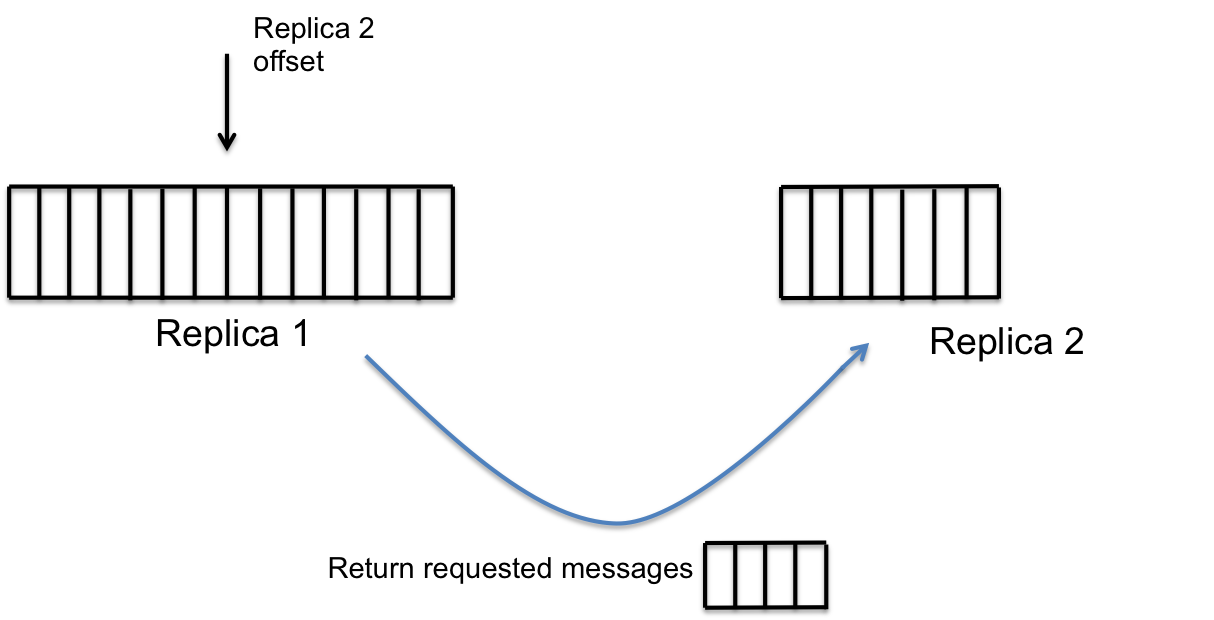 step6
step6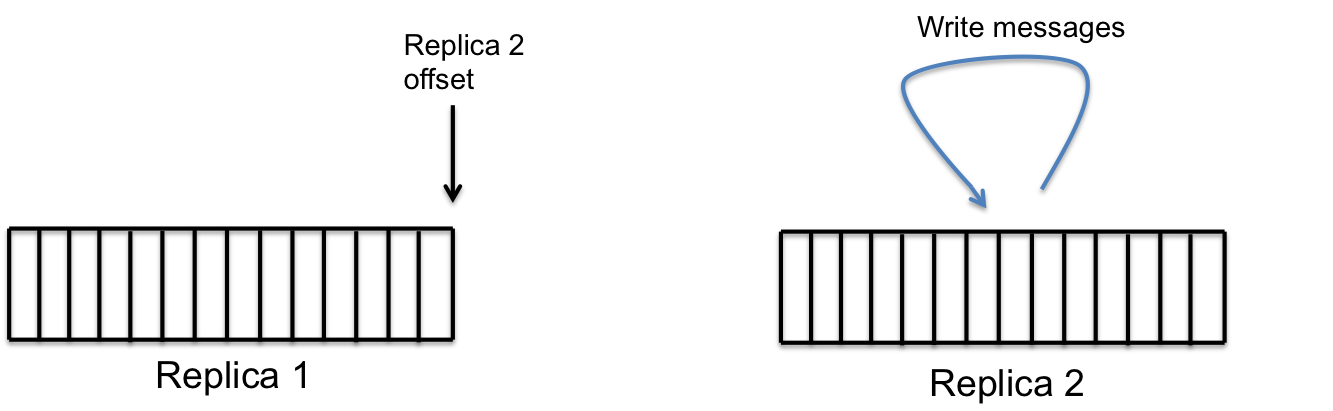 step7
step7
删除
- 删除的数据在落日志后还在磁盘上,空间没有释放
- 周期性扫描待删除的数据,跳过最近被删除的数据
- 删除数据会重写磁盘(至少把log中元数据相关清理掉),有模块会做流控防止io被删除占满
路由/前端
多主策略是如何实现的,如何仲裁
请求管理
- 路由会处理PUT、GET以及DELETE请求。
- 对于其中的每个请求类型,路由都会跟踪副本成功和失败的数量从而确定Quorum的值、维护分块的状态、生成对象id并在成功或失败的时候触发对应的回调
分块
- 对象会分解为块(chunk),每个块都能够跨分区独立地进行路由。
- 每个块都会有一个id来进行唯一标识。
- 路由会生成一个元数据对象,其中包含了块的列表以及它们所需的获取顺序。元数据对象存储为独立的blob,它的id也会作为blob的id。
- 在读取的时候,会得到元数据对象,然后检索各个块并返回给客户端
故障检测
- 故障检测的逻辑要负责主动识别宕机或状态出问题的资源。
- 资源可以是机器、磁盘或分区。
- 路由会将出现问题的资源标记为不可用,这样后续的请求就不会使用它们了
Quorum
- Ambry为写入和读取实现了一种多主人(multi-master)的策略。
- 这能够实现更高的可用性并减少端到端的延迟
- 这是通过减少一个额外的hop来实现的,
- 在基于主从结构(master slave)的系统中,往往会有这个额外的hop。请求通常会发往M个副本,然后等待至少N个成功的响应(这里N<=M)。
- 路由会优先使用本地数据中心的副本,向其发送请求,如果本地存储无法实现所需的Quorum的话,它会代理远程数据中心的访问
变更捕获
- 在每次成功的PUT或DELETE操作之后,路由会生成一个变更捕获(change capture)。
- 变更捕获中所包含的信息是blob id以及blob相关的元数据,这个信息可以被下游的应用所使用。
- 文件的写入删除会可以通知下游应用,比如kafka
安全控制
需求
- 多租户引入需要安全保证
- 使用SSL/TLS做传输的加密
- 对于哪些传输需要加密可配置,默认不加密
框架
数据传递需要考虑数据传输可以支持异步读写,内存拷贝减少,压力反馈。在层与层之间传递数据通过传递相关类实现,避免了过多的内存拷贝
Scaling Layer
- 中间层执行非阻塞操作,传递数据
- RestRequestHandler
- 处理由NIO layer发起的请求
- 内部由多个单元(类似多线程),单元多少影响数据吞吐量和延迟
- RestResponseHandler
- 处理由Remote Service Layer发起的response
- 内部由多个单元(类似多线程),单元多少影响数据吞吐量和延迟
- AsyncRequestResponseHandler
- 内部包含了RestRequestHandler和RestResponseHandler
- 处理请求和回复是异步的
- 请求由一个或多个单元处理,称为 AsyncRequestWorker
- AsyncRequestWorker需要维护状态:等待处理的请求/正在处理的请求/等待被发送出去,回复的请求
Remote Service Layer:
- 底层网络相关处理以及路由处理
- 这一层是单例无状态的,数据状态都存放于NIO layer初始化,用于数据传输的ReadableStreamChannel/RestResponseChannel上
NIO layer: 上层对外的网络服务
- 负责对外所有网络相关操作
- 接收端:比如HTTP编解码/接收来自client的请求,处理/向下传递
- 发送端:将回复发送给client
- 维护一些状态:
- 维护能用来处理请求的RestRequestHandler
- 每个channel也要维护其中请求的状态
- 正在处理的RestRequest
- RestResponseChannel对于每个请求也维护各自状态,方便处理对应的错误
部件交互
收包
NIO layer将包解出来,以RestRequest的形式搭配RestResponseChannel(用来传递回复消息)传递给RestRequestHandler,以做异步处理
包的异步处理
线程从request queue中取出rest request,做不同处理
- handleGet:AmbryBlobStorageService从request中解出blob id,做相应处理交互
- GET request:获取blob属性和内容,之前先创建 Callback object,待前面获取到了之后回调
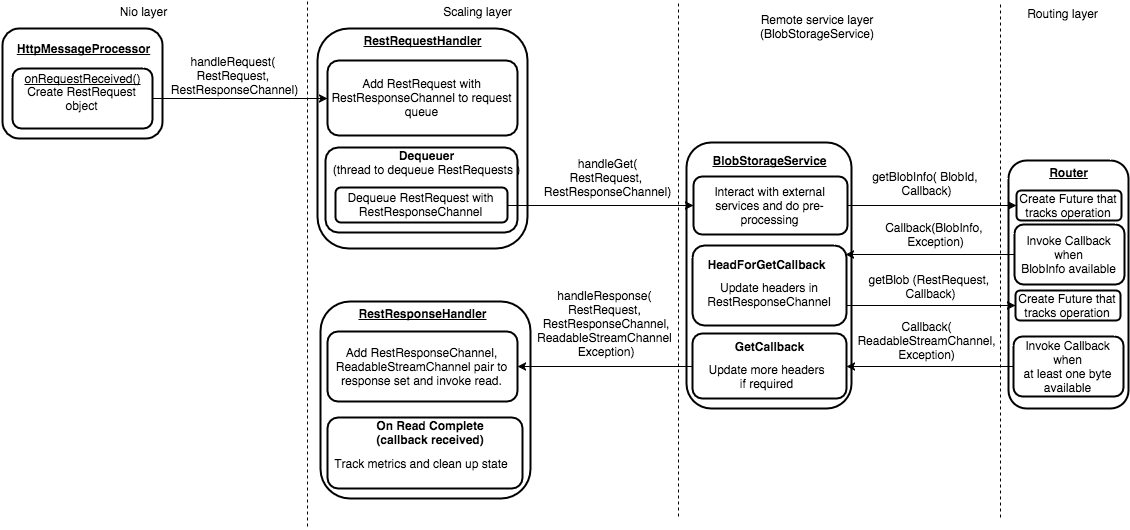 GET
GET
- handlePost: ReadableStreamChannel在这里的作用是在失败时或成功时返回结果以及反馈线路上的压力
- 在路由侧,接收推送的数据时,读不是有数据就去读的,而是等前一波数据推完了再读下一批,不通过事件机制读取数据
- 原因是这样可以给发送数据一侧反馈压力(利用tcp本身的机制)
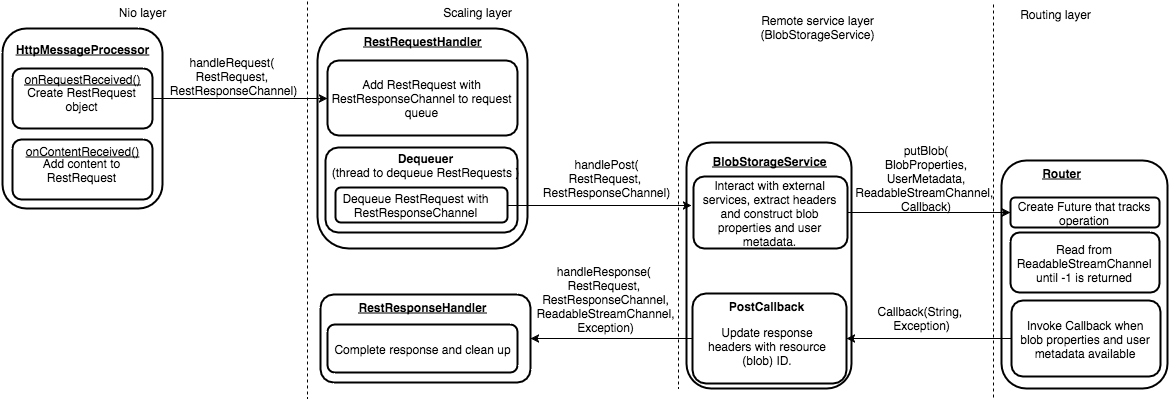 POST
POST
- handleDelete:
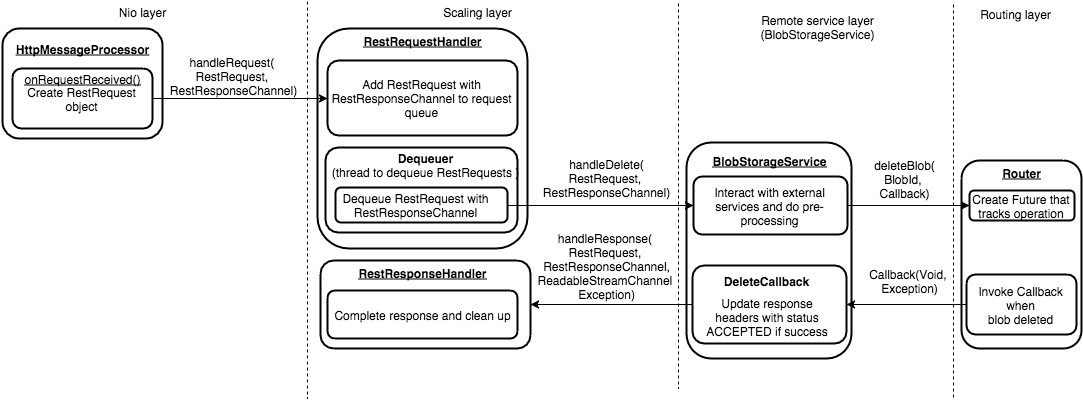 DELETE
DELETE
- handleHead:
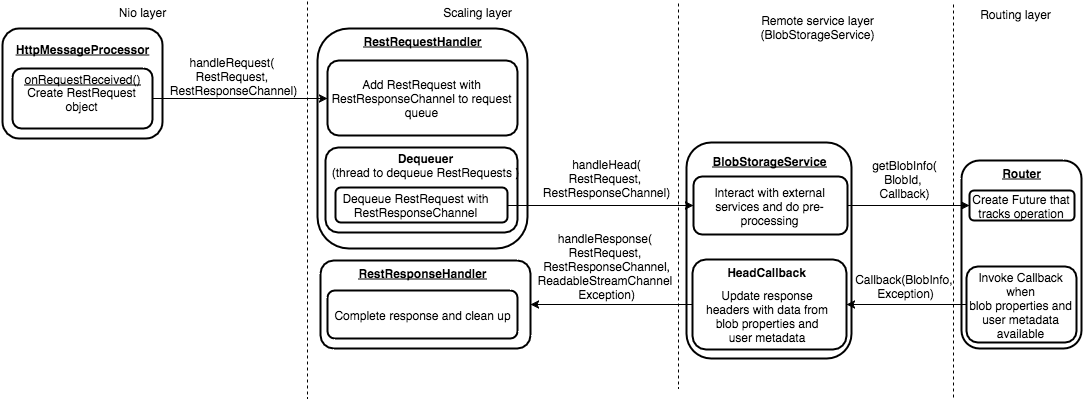 HEAD
HEAD


